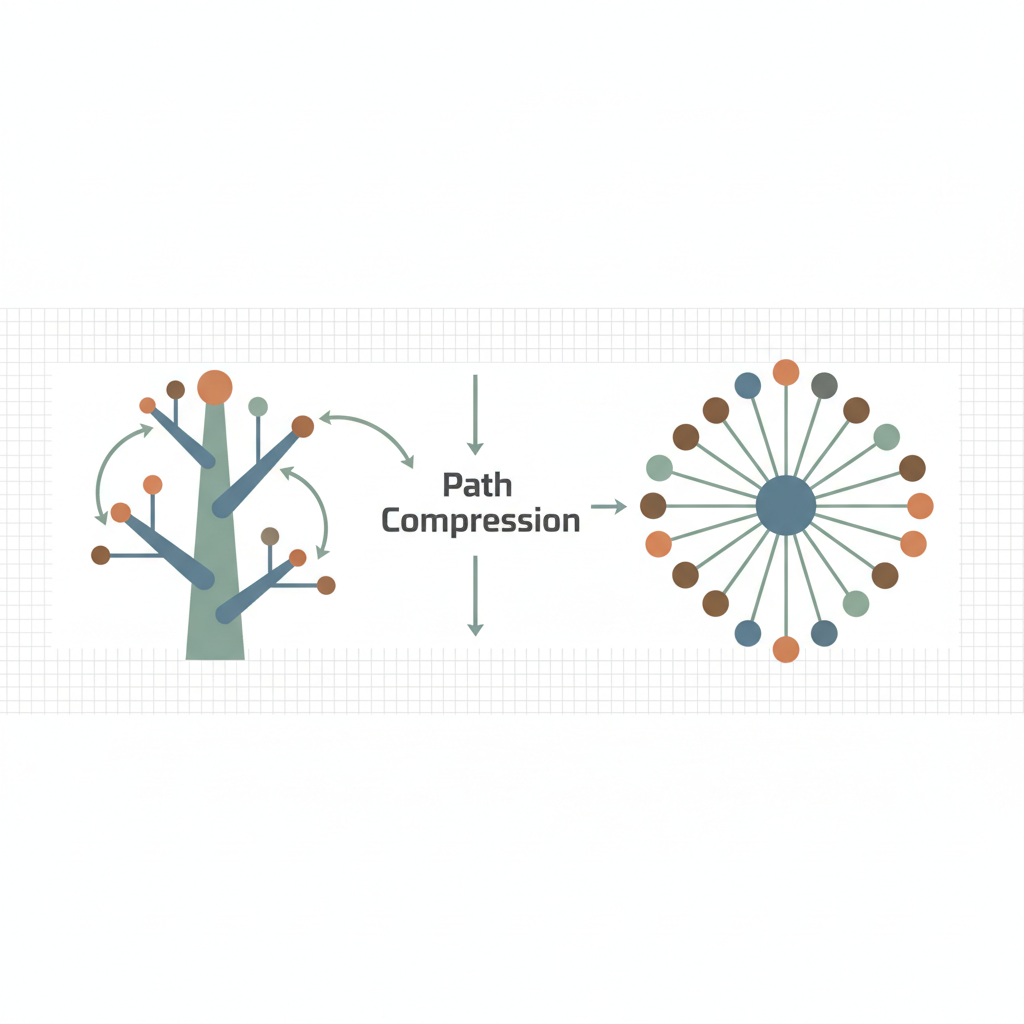
TL;DR — Path compression rewrites the parent pointers of every node visited during a find so that future queries jump straight to the set representative. The result is an almost flat forest where each operation runs in near‑constant amortized time.
Union‑Find (also called the Disjoint‑Set Union, DSU) is a cornerstone of graph algorithms, from Kruskal’s minimum‑spanning‑tree to offline connectivity queries. Its elegance lies in two simple operations—make‑set, union, and find—but the naïve implementation can degrade to linear time per operation. Path compression is the single most effective tweak that restores the data structure to near‑constant performance, and understanding why it works gives insight into amortized analysis and modern algorithmic engineering.
Union‑Find Basics
A Union‑Find structure maintains a collection of disjoint sets. Internally it stores each element as a node in a forest of rooted trees:
- Root of a tree is the representative of its set.
- Parent pointer of a non‑root node points toward the root.
- make‑set(x) creates a singleton tree where
xis its own root. - union(x, y) merges the two trees containing
xandy, usually by linking one root under the other. - find(x) follows parent pointers until it reaches the root, returning that representative.
A minimal Python implementation looks like this:
class UnionFind:
def __init__(self, n):
self.parent = list(range(n)) # each node is its own root
self.rank = [0] * n # optional heuristic for union
def find(self, x):
while self.parent[x] != x:
x = self.parent[x]
return x
def union(self, x, y):
rx, ry = self.find(x), self.find(y)
if rx == ry:
return
# union by rank (optional, improves balance)
if self.rank[rx] < self.rank[ry]:
self.parent[rx] = ry
elif self.rank[rx] > self.rank[ry]:
self.parent[ry] = rx
else:
self.parent[ry] = rx
self.rank[rx] += 1
Without any extra tricks, the find loop can walk up a chain of length O(n) in the worst case, especially after a series of unions that always attach the larger tree under the smaller one.
The Find Operation and Its Bottleneck
Consider the following sequence on 8 elements:
make-set(0)…make-set(7)
union(0,1) → parent[1]=0
union(1,2) → parent[2]=1
union(2,3) → parent[3]=2
…
union(6,7) → parent[7]=6
If each union always attaches the new element as a child of the previous root, the forest becomes a single linked list:
7 → 6 → 5 → 4 → 3 → 2 → 1 → 0
A find(7) now traverses 7 edges. Repeating find on any element suffers the same linear cost. The bottleneck is the depth of the tree.
Two classic heuristics mitigate depth:
- Union by rank (or size) – always attach the shallower tree under the deeper one.
- Path compression – flatten the tree during
find.
Union by rank guarantees that the tree height stays bounded by O(log n), but the constant factor can still be significant for massive inputs. Path compression pushes the bound down to α(n), the inverse Ackermann function, which is ≤ 4 for any realistic n.
Introducing Path Compression
Path compression rewrites the parent of every node visited while climbing toward the root, pointing it directly to the root. The next time any of those nodes participates in a find, the traversal stops immediately.
Classic Path Compression (Recursive)
The textbook recursive version is concise:
def find(self, x):
if self.parent[x] != x:
self.parent[x] = self.find(self.parent[x]) # path compression
return self.parent[x]
When find returns, the call stack unwinds, and each intermediate node’s parent entry is overwritten with the ultimate root. This transforms the deep chain into a star‑shaped tree in a single operation.
Iterative Path Halving
Recursive calls can be expensive in languages without tail‑call optimization. An iterative alternative, called path halving, updates every other node on the way up:
def find(self, x):
while self.parent[x] != x:
self.parent[x] = self.parent[self.parent[x]] # point to grandparent
x = self.parent[x]
return x
Each iteration halves the distance to the root, hence the name. In practice, path halving and the full compression above have indistinguishable asymptotic behavior, while the iterative version avoids recursion depth limits.
Complexity Analysis with Path Compression
The magic of path compression is revealed through amortized analysis, not worst‑case per‑operation bounds. The classic result (Tarjan, 1975) states:
Theorem – A sequence of m
make‑set,union, andfindoperations on n elements, using union by rank (or size) together with path compression, runs in O(m α(n)) time, where α is the inverse Ackermann function.
Because α(n) ≤ 4 for any n that fits in the observable universe, we treat it as a constant in practice. The proof hinges on two observations:
- Rank monotonicity – A node’s rank only increases when it becomes a root of a larger tree, and it never exceeds
⌊log₂ n⌋. - Potential function – Define a potential based on the rank of each node’s parent. Path compression dramatically reduces this potential each time a deep node is flattened.
Intuitively, each find pays a tiny amount of “credit” that is later spent when the same node’s ancestors are compressed. Over a long sequence, the credits balance out, yielding the near‑constant amortized cost.
A Quick Numerical Illustration
Suppose we have n = 1,000,000 elements and perform m = 10,000,000 mixed operations. Even if every operation were a find, the total work is bounded by:
10,000,000 × α(1,000,000) ≤ 10,000,000 × 4 = 40,000,000 primitive steps
That is roughly four primitive operations per query—a dramatic improvement over the naïve O(n) worst case.
Practical Implementations and Pitfalls
While the algorithmic idea is simple, production‑grade code must consider cache locality, thread safety, and memory layout.
Cache‑Friendly Layout
Storing parent and rank in contiguous numpy arrays (or std::vector in C++) improves spatial locality. A tight loop over find then benefits from CPU prefetching.
import numpy as np
class UF:
def __init__(self, n):
self.parent = np.arange(n, dtype=np.int32)
self.rank = np.zeros(n, dtype=np.int8)
def find(self, x):
while self.parent[x] != x:
self.parent[x] = self.parent[self.parent[x]]
x = self.parent[x]
return x
Thread Safety
Union‑Find is not inherently thread‑safe because union mutates two roots simultaneously. A common pattern is to partition the universe into disjoint shards, each processed by a single thread, then merge the shards with a final sequential pass. For truly concurrent workloads, lock‑free variants exist (e.g., using atomic compare‑and‑swap), but they add considerable complexity and are rarely needed for offline algorithms.
When Not to Use Path Compression
If the workload consists almost exclusively of union operations with very few finds, the overhead of updating parent pointers on each find can be unnecessary. In such cases, a plain union‑by‑rank forest suffices, and you can defer compression to a later “cleanup” phase.
Key Takeaways
- Path compression rewires every node visited during
findto point directly to the set representative, flattening the tree. - Combined with union by rank/size, it guarantees an amortized O(α(n)) time per operation, effectively constant for any practical input size.
- Both recursive full compression and iterative path halving achieve the same asymptotic bound; choose the style that fits your language’s recursion model.
- Real‑world implementations benefit from contiguous memory layouts and should be careful about thread safety when used in parallel contexts.
- The technique shines in algorithms that intermix many
finds andunions, such as Kruskal’s MST, offline LCA queries, and connectivity checks in dynamic graphs.
Further Reading
- Union–Find (Disjoint Set Union) – Wikipedia – comprehensive overview and pseudocode.
- Chapter 21: Data Structures – Introduction to Algorithms (CLRS, 3rd edition) – classic textbook treatment of union‑find with path compression.
- Tarjan’s original paper on amortized analysis of Union‑Find – the seminal work establishing the α(n) bound.