TL;DR — Quorum reads and writes are not a binary guarantee; they are statistical contracts that depend on replication factor, failure probability, and timing. By modelling these variables you can predict stale‑read risk and write durability, and make informed trade‑offs between latency and consistency.
In any system that spreads data across multiple machines, the promise of “quorum” is often taken at face value: a read that contacts a majority of replicas will see the most recent write, and a write that reaches a majority will survive node failures. The reality is more nuanced. Network partitions, clock skew, and transient outages turn the quorum guarantee into a probability distribution. This article unpacks the mathematics, walks through concrete examples, and shows how to apply the insights to Cassandra, DynamoDB, and other quorum‑based stores.
Understanding Quorum in Distributed Databases
The Theory Behind Quorum
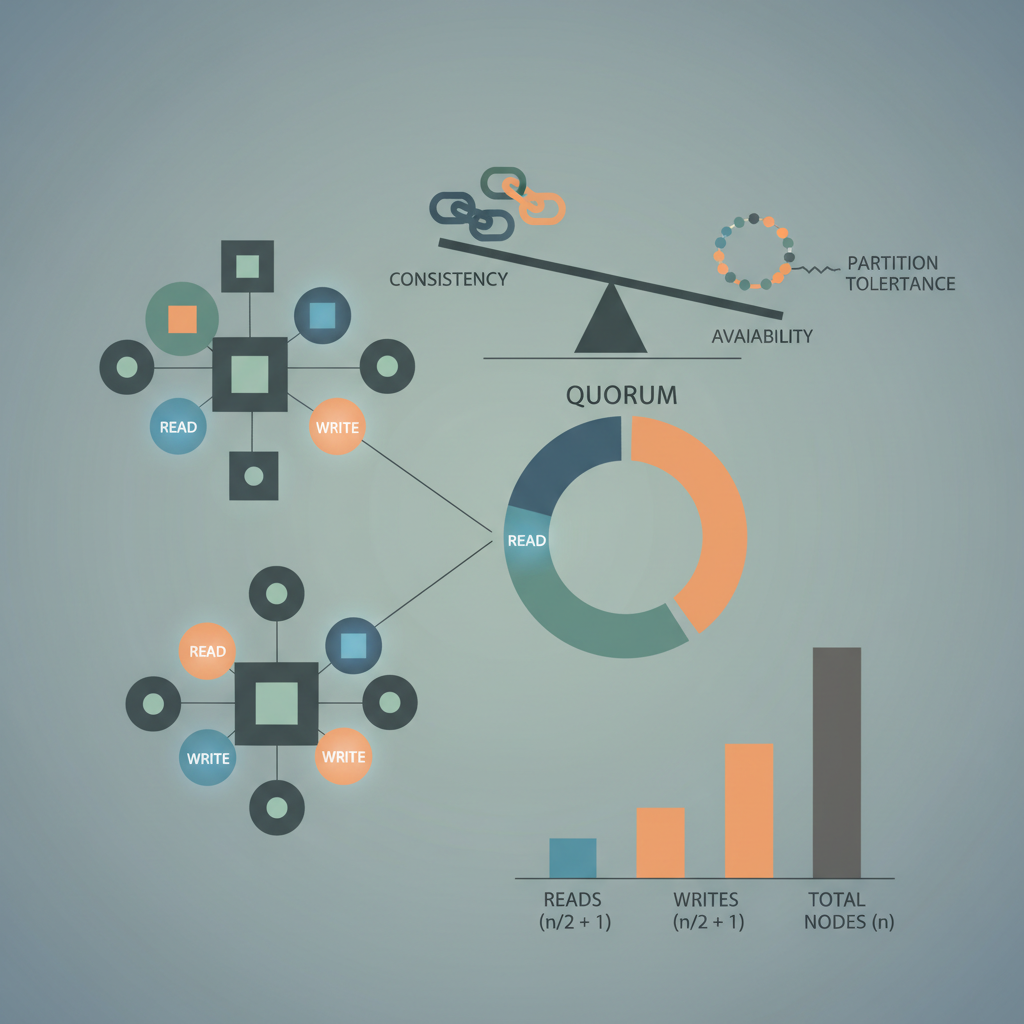
A quorum is defined by two numbers:
- N – the total number of replicas that store a given piece of data.
- Q – the number of replicas that must acknowledge a read or write operation for it to be considered successful.
In classic quorum systems, the rule R + W > N (where R is the read quorum size and W the write quorum size) guarantees that at least one replica participates in both the read and the write, ensuring linearizability under ideal conditions. This rule originates from the work of Gifford (1979) and underpins many modern NoSQL designs.
However, the rule assumes:
- No replica failures during the operation.
- Instantaneous