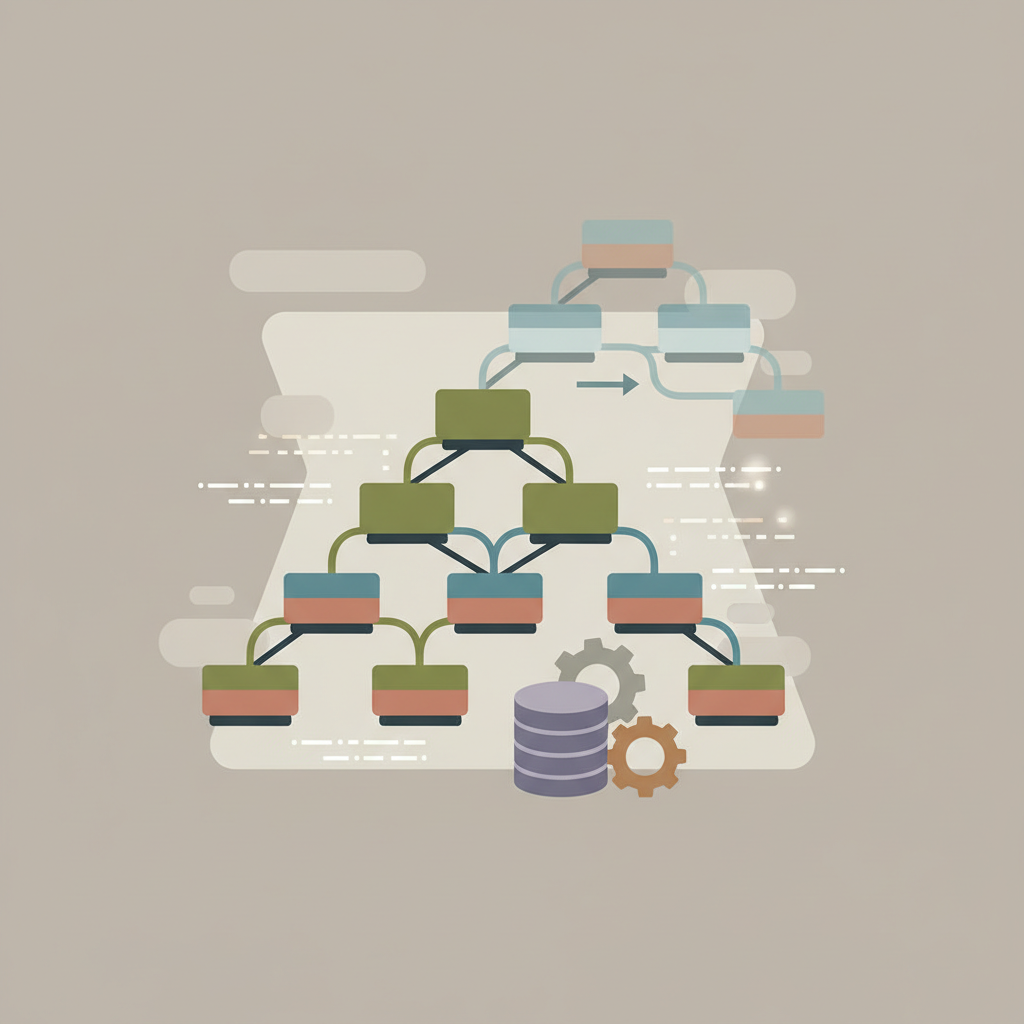
Why Copy-on-Write B-Trees Improve Database Concurrency Control
Copy-on-Write B‑Trees provide immutable snapshots for readers while writers work on new nodes, enabling high concurrency with minimal blocking.
Copy-on-Write B‑Trees provide immutable snapshots for readers while writers work on new nodes, enabling high concurrency with minimal blocking.

This article explains how copy‑on‑write B‑trees work, why they speed up database snapshots, and what trade‑offs developers should consider.

B‑trees keep disk reads low and writes efficient, making them the preferred index structure in databases and filesystems.

A deep dive into LSM trees versus B‑trees, focusing on write amplification, read/write trade‑offs, and their impact on modern distributed database design.
Introduction Vector indexing—whether for similarity search in recommendation engines, nearest‑neighbor queries in machine‑learning pipelines, or high‑dimensional feature retrieval in bioinformatics—has become a core workload in modern distributed systems. Traditional indexing structures (KD‑trees, LSH tables, inverted files) either suffer from poor cache locality or become bottlenecks when many threads try to update or query simultaneously. Enter the lock‑free concurrent B‑tree. By marrying the proven I/O‑optimal layout of B‑trees with the non‑blocking guarantees of lock‑free algorithms, we can achieve: ...