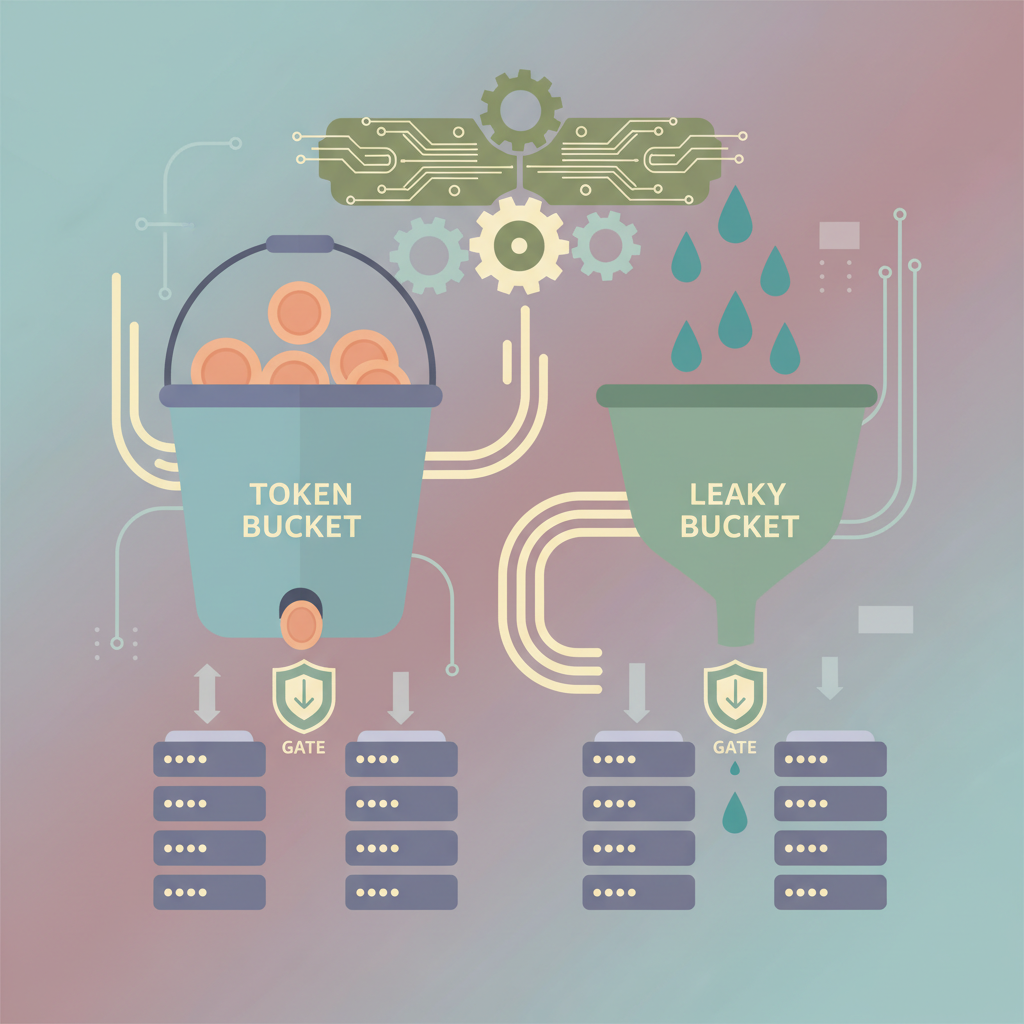
Mastering Token Bucket vs Leaky Bucket Rate Limiting: Architecture, Performance, and Production-Ready Patterns
A deep dive into token bucket and leaky bucket algorithms, showing how to choose, implement, and operate them at scale in modern cloud services.



